





随着大数据技术的飞速发展,实时计算已经成为企业数据处理的重要需求之一,Apache Spark作为一种高效的数据处理框架,其在实时计算领域的应用日益广泛,本文将重点讨论Spark实时计算与Hive集成,分析其在大数据处理领域的优势和应用场景,本文将分为三个要点进行深入探讨:Spark实时计算概述、Spark与Hive集成实践以及案例分析。
Spark实时计算概述
1、Spark实时计算概念
Spark实时计算是指利用Apache Spark框架进行数据流的处理和分析,以实现对数据的实时响应和处理,与传统的批处理不同,实时计算能够快速地处理数据流,实现对数据的即时分析和反馈。
2、Spark实时计算优势
(1)高处理速度:Spark基于内存的计算模式使其在处理大数据时具有极高的速度。
(2)灵活性强:支持多种数据类型和格式,能够灵活处理结构化、半结构化及非结构化数据。
(3)可扩展性好:基于分布式架构,可轻松扩展至数千个节点。
(4)容错性强:能够自动检测数据丢失或节点故障,保证数据处理的可靠性。
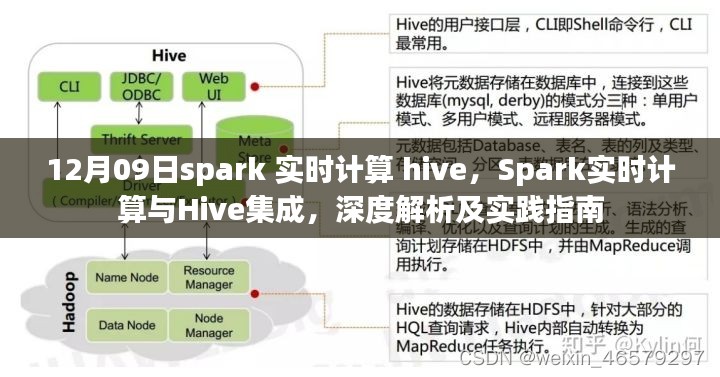
Spark与Hive集成实践
1、集成原理
Hive是一个基于Hadoop的数据仓库工具,用于处理大规模数据集,Spark与Hive集成后,可以利用Spark的高处理速度来加速Hive的数据查询和分析,集成过程主要通过Spark SQL和Hive的交互实现。

2、集成步骤
(1)环境配置:确保Spark和Hive环境已安装并配置妥当。
(2)数据同步:确保Spark能够访问Hive中的数据表。
(3)查询优化:利用Spark SQL优化Hive查询性能。
(4)结果输出:将查询结果写入Hive表或输出到其他存储介质。
要点详解
要点一:Spark实时计算的应用场景
1、实时数据分析:利用Spark实时计算进行数据分析,帮助企业快速做出决策。
2、实时推荐系统:基于用户行为数据,利用Spark实时计算进行推荐算法处理,实现个性化推荐。
3、物联网数据处理:处理海量物联网数据,实现设备的实时监控和管理。
要点二:Spark与Hive集成中的技术细节与优化策略
1、数据分区与倾斜问题处理:在进行大数据处理时,需合理设计数据分区策略,避免数据倾斜问题。
2、查询性能优化:利用Spark SQL的查询优化策略,提高Hive查询性能。
3、数据序列化与反序列化优化:优化数据序列化和反序列化过程,提高数据处理速度。
要点三:案例分析与实践经验分享
某电商企业通过集成Spark和Hive,实现了实时数据分析,通过Spark实时计算,企业能够迅速响应市场变化,优化商品推荐策略,提高用户满意度和销售额,实践过程中,企业采用了以下策略:
1、利用Spark Streaming实现实时数据流处理。
2、通过Spark SQL与Hive集成,实现数据的即时查询和分析。
3、采用分布式缓存技术,提高数据访问速度。
4、结合业务需求,设计合理的数据分区策略。
通过实践,企业取得了显著的成果:数据处理速度大幅提升,查询响应时间缩短;个性化推荐策略更加精准;用户满意度和销售额均有显著提升。
本文详细探讨了Spark实时计算与Hive集成的原理、实践及案例,通过集成Spark和Hive,企业可以充分利用两者的优势,实现高效、实时的数据处理和分析,随着大数据技术的不断发展,相信Spark与Hive的集成将在更多领域得到应用和推广。








 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...